Data replication technologies: What they are and how to use them
Data replication can play a big role in a disaster recovery plan, so make sure you're familiar with the different types of replication and where they work best.
Data replication is the process of copying data from one location to another so you have multiple up-to-date copies. For disaster recovery, replication usually occurs between a primary storage location and a secondary off-site location, which can be hosted by a cloud provider.
Replication is a key technology for disaster recovery and often works in combination with data deduplication, virtual servers, snapshots or the cloud to carry out its role in a disaster recovery plan.
Below, we cover types of data replication technologies, available products and where each type of technology works best. With this helpful guide, learn how to choose the best replication product; the differences between host-, array- and network-based data replication; and how technologies like data deduplication and virtual servers are used for replication and disaster recovery in the data center.
Data replication in DR
Replicas play an important role in disaster recovery. The unexpected nature of disruptive incidents mean that they may not be preventable, but thorough preparation can see you through. Data replication is one way to ensure that you are prepared for a disaster.
Replication creates copies of data at varying frequencies, depending on the data in question and the industry of the organization backing it up. Ideally, data is as up to date as possible, so if you create copies of data frequently, that information won't be obsolete once it is recovered.
Because replicas can often be saved in different locations, they are a good fit for disaster recovery plans that involve a secondary data center or off-site recovery location like the cloud. When deciding between data replication technologies, be sure to keep your DR planning and strategy in mind.
Several factors determine what type of data replication product is best for an organization's data center.
Synchronous and asynchronous replication
Several factors determine what type of data replication product is best for an organization's data center. There are two types of data replication products: synchronous and asynchronous. Synchronous replication writes data to the primary and secondary sites at the same time. With asynchronous replication, there is a delay before the data gets written to the secondary site.
Both types of replication have advantages and disadvantages in a disaster recovery plan. While data is always current between sites with synchronous replication, it is more expensive than asynchronous replication, introduces latency that slows down the primary application and only works over distances up to 300 km. Synchronous replication is preferred for applications with low recovery time objectives that can't abide data loss.
Because asynchronous replication is designed to work over longer distances and requires less bandwidth, it is often a better option for disaster recovery. However, asynchronous replication risks a loss of data during a system outage because data at the target device isn't up to date with the source data. If you're looking for high availability and consistency between primary and secondary copies, synchronous is your best bet.
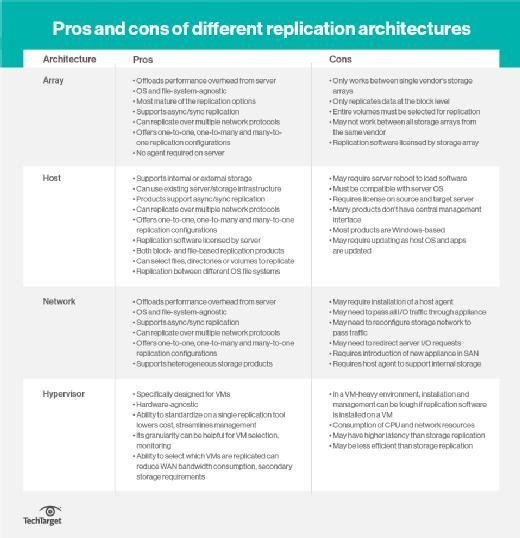
Array-, host- and network-based replication
Another differentiator between data replication technologies is where the replication takes place. Replication occurs in one of three places: in the storage array, at the host (server) or in the network. Each replication location has benefits and drawbacks. Most replication still occurs at the array, although that is changing as host- and network-based options improve.
While host-based replication is typically the cheaper option of the three, it can negatively affect server performance and is more vulnerable to viruses and crashes. Array-based replication is less likely to suffer disruptions but is provided by a single vendor and limited to homogeneous storage environments. Most enterprise data storage vendors include array-based replication software on their high-end and midrange storage arrays.
Network-based replication is better if you're not looking to be locked into one vendor, as it has universal compatibility. However, while it can no longer be considered new, network-based replication does not have as many products available on the market and doesn't garner as much attention as its counterparts. Replication on the network requires an additional device, either an intelligent switch or an inline appliance.
Disk array-based replication usually replicates only between the same type of array, while network-based and host-based replication work across storage platforms. Another difference is host replication only supports asynchronous replication, while array and network replication can be asynchronous or synchronous.
Hypervisor-based replication, designed specifically for virtual machines, is another option today. It is hardware agnostic but lacks the efficiency and performance of the alternative data replication technologies.
Snapshot replication
Snapshots are a commonly used reference marker and can act as a table of contents for data. They can be used for a number of purposes, but data protection is the primary use for storage snapshots. When used for disaster recovery, a snapshot can provide you with an accessible copy of data after a file is lost or corrupted.
Using snapshot replication, multiple copies of data can be placed in multiple locations, such as a primary data center or secondary location. With snapshots, different types of storage systems can back up and recover from different sites, or both systems can replicate to the same sites.
Data deduplication and replication
Data deduplication is often combined with data replication technologies for disaster recovery purposes. Deduplication reduces the amount of data that gets replicated and lowers the bandwidth requirement to copy data offsite.
There are drawbacks to the dedupe/replication combination. Inline deduplication, which takes place while data is being written to disk, can impact backup performance. Post-process deduplication, which takes place after the backup completes, can delay replication. Still, data that is deduplicated and replicated off site can be recovered much faster than data backed up to tapes and stored off site for disaster recovery.
Leading deduplication software vendors include Druva, SolarWinds, IBM, and ExaGrid.
Top vendors to consider for replicating virtual machines include Veeam, Zerto, Microsoft, Dell EMC and VMware.
Cloud storage and data replication
The cloud also fits with replication, because it can remove cost and complexity from disaster recovery. It alleviates the need to acquire and manage an off-site location.
Host-based replication is generally the best fit for disaster recovery through the cloud, because storage array- and network-based replication require devices at the source and target locations. Host-based replication lets you move data from standard servers in your environment to the provider's servers off site.
Dig Deeper on Disaster recovery facilities and operations