
Gajus - stock.adobe.com
Risk management vs. risk assessment vs. risk analysis
Understanding risk is the first step to making informed budget and security decisions. Explore the differences between risk management vs. risk assessment vs. risk analysis.

Risk management, risk assessment and risk analysis are often used interchangeably, leading some to believe they are synonyms. In reality, each is its own unique process that IT and business leaders need to understand.
At their most basic, a risk assessment is the information, a risk analysis is the processing and risk management is the plan. Below, learn more about the differences between them and how, in conjunction, they lead to more successful infosec programs.
What is a risk assessment?
A risk assessment involves evaluating existing security controls and assessing their adequacy relative to the potential threats of the organization. It also covers potential consequences of the risks if they go unmitigated.
The goal of a risk assessment will depend on the specific organization and its industry, as well as its compliance regulations. Common goals include developing a risk profile, inventorying IT and data assets, or supporting the costs of security countermeasures.
To conduct a risk assessment, companies should use a risk assessment framework (RAF), which helps prioritize and share information gleaned during an assessment about the security risks to IT infrastructure in particular. Ideally, the RAF includes language that is usable to people with technical and nontechnical backgrounds.
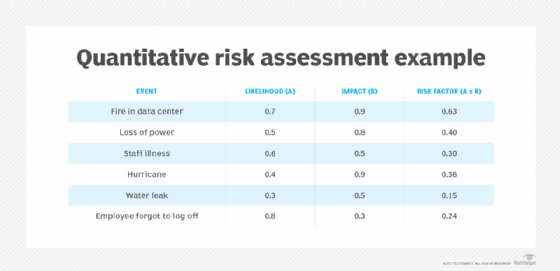
What is a risk analysis?
A risk analysis involves identifying the most probable threats to an organization and analyzing the related vulnerabilities of the organization to these threats. Risk analysis is used to estimate and manage the cost of potential threats, which influences company decision-making. To properly analyze risk, organizations must calculate the probability potential negative events could impact their risk profile. These events range from natural disasters to public health issues to events caused by humans, including malicious or accidental insider threats.
The first step in a risk analysis is to conduct a risk assessment survey. Second, organizations identify and analyze the results. Third, they develop and subsequently enact a risk management plan. Finally, they must continually monitor the risks and update their plans accordingly.
There are two main schools of risk analysis: qualitative and quantitative. Qualitative risk analyses attempt to predict the likelihood of a risk occurring against its potential effects. The predicted effects are ranked low, medium or high. Quantitative analyses seek to put an estimated price tag on each risk's monetary impact.
What is risk management?
Risk management is the systematic application of management policies, procedures and practices to manage risk. Managing risk requires an organization to contextualize, identify, evaluate, treat, monitor and communicate risk.
To carry out these requirements, organizations can implement a few different strategies. Commonly used risk management strategies include risk avoidance, risk reduction, risk sharing and risk retaining. The risk management plan must address a few critical elements of the organization's risk profile, specifically what steps need to be taken to manage risk and how to budget for those steps.
During the process of orchestrating a risk management strategy, organizations should identify their most critical threats and where surprise costs may turn up. What is learned during this planning process can be used to shore up defenses against newly discovered risks or to request additional budget to better address those risks.
How do they relate?
Though risk assessment, analysis and management all have different functions, they work best when they inform each other. Without the information from risk assessments and investigation of that information during risk analysis, a risk management plan is nearly obsolete.
This is important for infosec professionals to understand, especially if they have their hands in only one or two of the tasks. To best mitigate risk, the teams conducting risk assessments, analyses and management should know how their efforts affect the others and the organization's defenses as a whole.







