fault tolerance

What is fault tolerance?
Fault tolerance is the capability of a system to deliver uninterrupted service despite one or more of its components failing.
Fault tolerance also resolves potential service interruptions related to software or logic errors. The purpose is to prevent catastrophic failure that could result from a single point of failure.
Fault-tolerant systems are designed to compensate for multiple failures. Such systems automatically detect a failure of the central processing unit, input/output (I/O) subsystem, memory cards, motherboard, power supply or network components. The failure point is identified, and a backup component or procedure immediately takes its place with no loss of service.
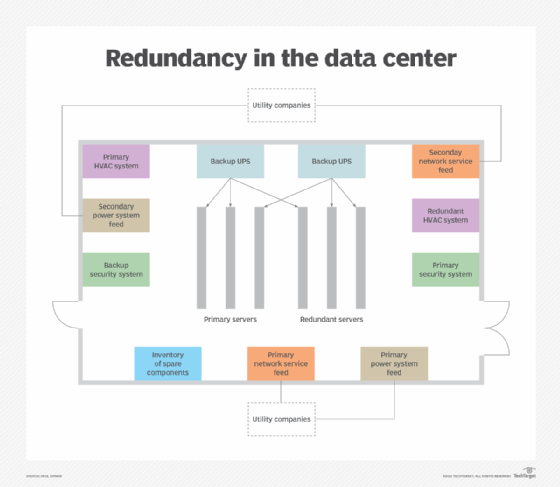
To ensure fault tolerance, enterprises need to purchase an inventory of formatted computer equipment and a secondary uninterruptible power supply device. The goal is to prevent the crash of key systems and networks, focusing on issues related to uptime and downtime.
Fault tolerance can be provided with software, embedded in hardware or enabled by some combination of the two.
In a software implementation, the operating system (OS) provides an interface that allows a programmer to checkpoint critical data at predetermined points within a transaction. In a hardware implementation, the programmer does not need to be aware of the fault-tolerant capabilities of the machine.
At a hardware level, fault tolerance is achieved by duplexing each hardware component. Disks are mirrored. Multiple processors are grouped together, and their outputs are compared for correctness. When an anomaly occurs, the faulty component is determined and taken out of service, but the machine continues to function as usual.
Fault tolerance vs. high availability
Fault tolerance is closely associated with maintaining business continuity via highly available computer systems and networks. Fault-tolerant environments restore service instantaneously following a service outage. A high availability environment strives for 99.999% of operational service.
In a high availability cluster, sets of independent servers are loosely coupled together to guarantee systemwide sharing of critical data and resources. The clusters monitor each other's health and provide fault recovery to ensure applications remain available. Conversely, a fault-tolerant cluster consists of multiple physical systems that share a single copy of a computer's OS. Software commands issued by one system are also executed on the other systems.
The tradeoff between fault tolerance and high availability is cost. Systems with integrated fault tolerance incur a higher cost due to the inclusion of additional hardware.
Fault tolerance vs. graceful degradation
Fault tolerance is often used synonymously with graceful degradation, although the latter is more aligned with the more holistic discipline of fault management, which aims to detect, isolate and resolve problems preemptively.
A fault-tolerant system swaps in backup componentry to maintain high levels of system availability and performance. Graceful degradation allows a system to continue operations, albeit in a reduced state of performance.
Matching data protection and fault tolerance
Fault tolerance hinges on redundancy. Information is redundantly protected via data replication or synchronous mirroring of volumes to an off-site data center. For physical redundancy, extra hardware equipment remains on standby for failover of operational systems.
Data backup is frequently combined with redundancy. Both strategies are intended as a safeguard against data loss, although backup tends to focus on point-in-time recovery. This includes granular recovery of a discrete data object. Redundant systems are engineered specifically for application workloads that tolerate very little downtime.
When implementing fault tolerance, enterprises should match data availability requirements to the appropriate level of data protection with redundant array of independent disks (RAID). The RAID technique ensures data is written to multiple hard disks, both to balance I/O operations and boost overall system performance.
Organizations that prioritize fault tolerance above speed and performance would be best served by RAID 1 disk mirroring or by RAID 10, which combines disk mirroring and disk striping. If fault tolerance and system performance are equally important, an enterprise might combine RAID 10 with RAID 6, or double-parity RAID, which tolerates two disk failures before data is lost. Aside from higher cost, the other drawback is that data writes occur more slowly to the RAID set.
Aside from hardware, a fault-tolerant architecture should be coordinated with regularly scheduled backups of critical data, such as including a mirrored copy at a secondary or alternate location. Security needs to be part of the planning to prevent unauthorized access, as well as to apply antivirus tools and the most recent version of the computing system's OS.
Which industries depend on system fault tolerance?
Fault tolerance refers not only to the consequence of having redundant equipment, but also to the ground-up methodology that computer makers use to engineer and design their systems for reliability. Fault tolerance is a required design specification for computer equipment used in online transaction processing systems, such as airline flight control and reservation systems. Fault-tolerant systems are also widely used in sectors such as distribution and logistics, electric power plants, heavy manufacturing, industrial control systems, and retailing.






