High availability guidelines and VMware HA best practices
Elias Khnaser discusses VMware High Availability best practices in this chapter excerpt. After you read the excerpt, download the full backup and high availability chapter.
VMware High Availability (HA) is a utility that eliminates the need for dedicated standby hardware and software in a virtualized environment. VMware HA is often used to improve reliability, decrease downtime in virtual environments and improve disaster recovery/business continuity.
This chapter excerpt from VCP4 Exam Cram: VMware Certified Professional, 2nd Edition by Elias Khnaser explores VMware HA best practices.
VMware High Availability deals primarily with ESX/ESXi host failure and what happens to the virtual machines (VMs) that are running on this host. HA can also monitor and restart a VM by checking whether the VMware Tools are still running. When an ESX/ESXi host fails for any reason, all the running VMs also fail. VMware HA ensures that the VMs from the failed host are capable of being restarted on other ESX/ESXi hosts.
Many people mistakenly confuse VMware HA with fault tolerance. VMware HA is not fault tolerant in that if a host fails, the VMs on it also fail. HA deals only with restarting those VMs on other ESX/ESXi hosts with enough resources. Fault tolerance, on the other hand, provides uninterruptible access to resources in the event of a host failure.
 Click on the book cover image above
Click on the book cover image above
to download Elias Khnaser's entire chapter
on backup and high availability.
VMware HA maintains a communication channel with all the other ESX/ESXi hosts that are members of the same cluster by using a heartbeat that it sends out every 1 second in vSphere 4.0 or every 10 seconds in vSphere 4.1 by default. When an ESX server misses a heartbeat, the other hosts wait 15 seconds for the other host to respond again. After 15 seconds, the cluster initiates the restart of the VMs on the failing ESX/ESXi host on the remaining ESX/ESXi hosts in the cluster. VMware HA also constantly monitors the ESX/ESXi hosts that are members of the cluster and ensures that resources are always available to satisfy requirements in the event of a host failure.
Virtual Machine Failure Monitoring
Virtual Machine Failure Monitoring is technology that is disabled by default. Its function is to monitor virtual machines, which it queries every 20 seconds via a heartbeat. It does this by using the VMware Tools that are installed inside the VM. When a VM misses a heartbeat, VMware HA deems this VM as failed and attempts to reset it. Think of Virtual Machine Failure Monitoring as sort of High Availability for VMs.
Virtual Machine Failure Monitoring can detect whether a virtual machine was manually powered off, suspended, or migrated, and thereby does not attempt to restart it.
VMware HA configuration prerequisites
HA requires the following configuration prerequisites before it can function properly:
- vCenter: Because VMware HA is an enterprise-class feature, it requires vCenter before it can be enabled.
- DNS resolution: All ESX/ESXi hosts that are members of the HA cluster must be able to resolve one another using DNS.
- Access to shared storage: All hosts in the HA cluster must have access and visibility to the same shared storage; otherwise, they would have no access to the VMs.
- Access to same network: All ESX/ESXi hosts must have the same networks configured on all hosts so that when a VM is restarted on any host, it again has access to the correct network.
Service Console redundancy
Recommended practice dictates that the Service Console (SC) have redundancy. VMware HA complains and issues a warning if it detects that the Service Console is configured on a vSwitch with only one vmnic. As Figure 1 shows, you can configure Service Console redundancy in one of two ways:
- Create two Service Console port groups, each on a different vSwitch.
- Assign two physical network interface cards (NICs) in the form of a NIC team to the Service Console vSwitch.
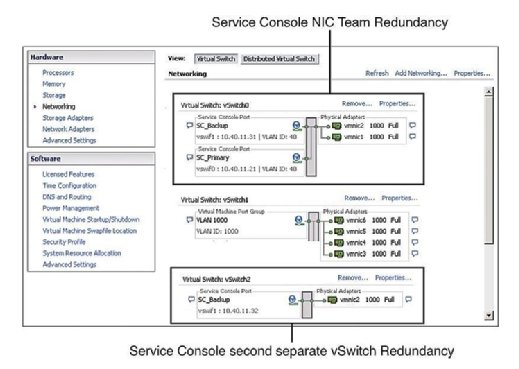
In both cases, you need to configure the entire IP stack with IP address, subnet, and gateway. The Service Console vSwitches are used for heartbeats and state synchronization and use the following ports:
- Incoming TCP port 8042
- Incoming UDP port 8045
- Outgoing TCP port 2050
- Outgoing UDP port 2250
- Incoming TCP port 8042–8045
- Incoming UDP port 8042–8045
- Outgoing TCP port 2050–2250
- Outgoing UDP port 2050–2250
Failure to configure SC redundancy results in a warning message when you enable HA. So, to avoid seeing this error message and to adhere to best practice, configure the SC to be redundant.
Host failover capacity planning
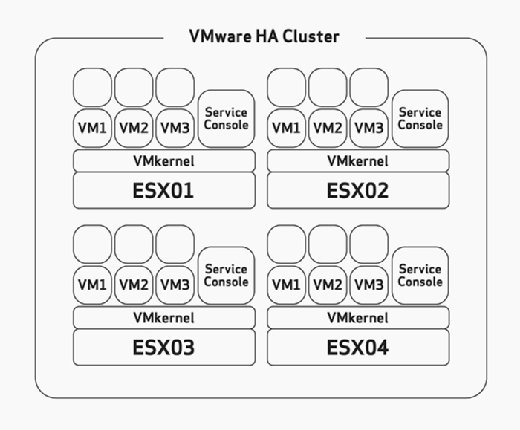
When configuring HA, you have to manually configure the maximum host failure tolerance. This is a task that you should thoughtfully consider during the hardware sizing and planning phase of your deployment. This would assume that you have built your ESX/ESXi hosts with enough resources to run more VMs than planned to be able to accommodate HA. For example, in Figure 2, notice that the HA cluster has four ESX hosts and that all four of these hosts have enough capacity to run at least three more VMs. Because they are all already running three VMs, that means that this cluster can afford the loss of two ESX/ESXi hosts because the remaining two ESX/ESXi hosts can power on the six failed VMs with no problem if failure occurs.
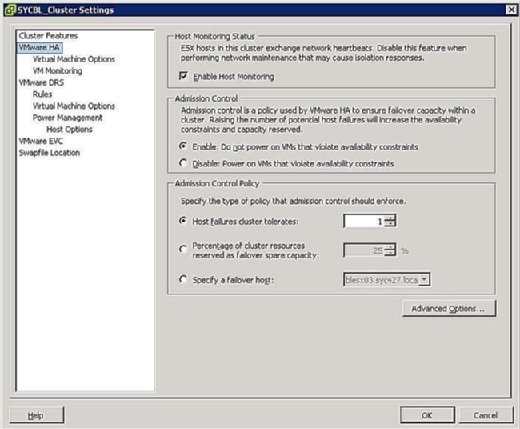
During the configuration phase of the HA cluster, you are presented with a screen similar to that shown in Figure 3 that prompts you to define two clusterwide configurations as follows:
- Host Monitoring Status:
- Enable Host Monitoring: This setting enables you to control whether the HA cluster should monitor the hosts for a heartbeat. This is the cluster's way of determining whether a host is still active. In some cases, when you are running maintenance tasks on ESX/ESXi hosts, it might be desirable to disable this option to avoid isolating a host.
- Admission Control:
- Enable: Do not power on VMs that violate availability constraints: Selecting this option indicates that if no resources are available to satisfy a VM, it should not be powered on.
- Disable: Power on VMs that violate availability constraints: Selecting this option indicates that you should power on a VM even if you have to overcommit resources.
- Admission Control Policy:
- Host failures cluster tolerates: This setting enables you to configure how many host failures you want to tolerate. The allowed settings are 1 through 4.
- Percentage of cluster resources reserved as failover spare capacity: Selecting this option indicates that you are reserving a percentage of the total cluster resources in spare for failover. In a four-host cluster, a 25% reservation indicates that you are setting aside a full host for failover. If you want to set aside fewer, you can choose 10% of the cluster resources instead.
- Specify a failover host: Selecting this option indicates that you are selecting a particular host as the failover host in the cluster. This might be the case if you have a spare host or have a particular host that has significantly more compute and memory resources available.
Host isolation
A network phenomenon known as a split-brain occurs when the ESX/ESXi host has stopped receiving a heartbeat from the rest of the cluster. The heartbeat is queried for every one second in vSphere 4.0 or 10 seconds in vSphere 4.1. If a response is not received, the cluster thinks the ESX/ESXi host has failed. When this occurs, the ESX/ESXi host has lost its network connectivity on its management interface. The host might still be up and running and the VMs might not even be affected considering they might be using a different network interface that has not been affected. However, vSphere needs to take action when this happens because it believes a host has failed. For that matter, the host isolation response was created. Host isolation response is HA's way of dealing with an ESX/ESXi host that has lost its network connection.
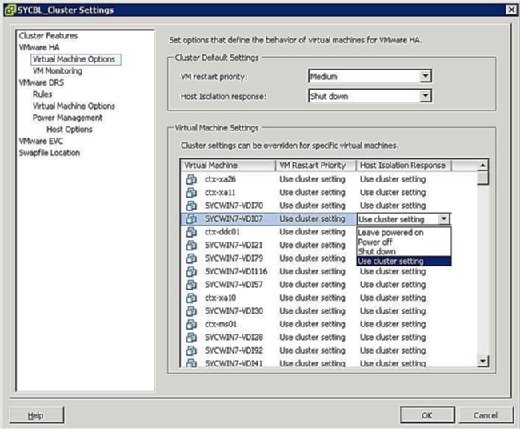
You can control what happens to VMs in the event of a host isolation. To get to the VM Isolation Response screen, right-click the cluster in question and click on Edit Settings. You can then click Virtual Machine Options under the VMware HA banner in the left pane. You can control options clusterwide by setting the host isolation response option accordingly. This is applied to all the VMs on the affected host. That being said, you can always override the cluster settings by defining a different response at the VM level.
As shown in Figure 4, your Isolation Response options are as follows:
- Leave Powered On: As the label implies, this setting means that in the event of host isolation, the VM remains powered on.
- Power Off: This setting defines that in the event of an isolation, the VM is powered off. This is a hard power off.
- Shut down: This setting defines that in the event of an isolation, the VM is shut down gracefully using VMware Tools. If this task is not successfully completed within five minutes, a power off is immediately executed. If VMware Tools is not installed, a power off is executed instead.
- Use Cluster Setting: This setting forwards the task to the clusterwide setting defined in the window shown previously in Figure 4.
In the event of an isolation, this does not necessarily mean that the host is down. Because the VMs might be configured with different physical NICs and connected to different networks, they might continue to function properly; you therefore have to consider this when setting the priority for isolation. When a host is isolated, this simply means that its Service Console cannot communicate with the rest of the ESX/ESXi hosts in the cluster.
Virtual machine recovery priority
Should your HA cluster not be able to accommodate all the VMs in the event of a failure, you have the ability to prioritize on VMs. The priorities dictate which VMs are restarted first and which VMs are not that important in the event of an emergency. These options are configured on the same screen as the Isolation Response covered in the preceding section. You can configure clusterwide settings that will be applied to all VMs on the affected host, or you can override the cluster settings by configuring an override at the VM level.
You can set a VM's restart priority to one of the following:
- High: VMs with a high priority are restarted first.
- Medium: This is the default setting.
- Low: VMs with a low priority are restarted last.
- Use Cluster Setting: VMs are restarted based on the setting defined at the cluster level defined in the window shown in the figure below.
- Disabled: The VM does not power on.
The priority should be set based on the importance of the VMs. In other words, you might want to restart domain controllers and not restart print servers. The higher priority virtual machines are restarted first. VMs that can tolerate remaining powered off in the event of an emergency should be configured to remain powered off to conserve resources.
MSCS clustering
The main purpose of a cluster is to ensure that critical systems remain online at any cost and at all times. Similar to physical machines that can be clustered, virtual machines can also be clustered with ESX using three different scenarios:
- Cluster-in-a-box: In this scenario, all the VMs that are part of the cluster reside on the same ESX/ESXi host. As you might have guessed, this immediately creates a single point of failure: the ESX/ESXi host. As far as shared storage is concerned, you can use virtual disks as shared storage in this scenario, or you can use Raw Device Mapping (RDM) in virtual compatibility mode.
- Cluster-across-boxes: In this scenario, the cluster nodes (VMs that are members of the cluster) reside on multiple ESX/ESXi hosts, whereby each of the nodes that make up the cluster can access the same storage so that if one VM fails, the other can continue to function and access the same data. This scenario creates an ideal cluster environment by eliminating a single point of failure. Shared storage is a prerequisite in this and must reside on Fibre Channel SAN. You also must use an RDM in Physical or Virtual Compatibility Mode as virtual disks are not a supported configuration for shared storage. Whereby each of the nodes that make up the cluster can access the same storage so that if one VM fails, the other can continue to function and access the same data.
- Physical-to-virtual cluster: In this scenario, one member of the cluster is a virtual machine, whereas the other member is a physical machine. Shared storage is a prerequisite in this scenario and must be configured as an RDM in Physical Compatibility Mode.
Whenever you are designing a clustering solution you need to address the issue of shared storage, which would allow multiple hosts or VMs access to the same data. vSphere offers several methods by which you can provision shared storage as follows:
- Virtual disks: You can use a virtual disk as a shared storage area only if you are doing clustering in a box -- in other words, only if both VMs reside on the same ESX/ESXi host.
- RDM in Physical Compatibility Mode: This mode enables you to attach a physical LUN directly into a VM or physical machine. This mode prevents you from using functionality such as snapshots and is ideally used when one member of the cluster is a physical machine while the other is a VM.
- RDM in Virtual Compatibility Mode: This mode enables you to attach a physical LUN directly into a VM or physical machine. This mode gives you all the benefits of virtual disks running on VMFS including snapshots and advanced file locking. The disk is accessed via the hypervisor and is ideal when configuring a cluster-across-boxes scenario where you need to give both VMs access to shared storage.
At the time of this writing, the only VMware-supported clustering service is Microsoft Clustering Services (MSCS). You can consult the VMware white paper "Setup for Failover Clustering and Microsoft Cluster Service."
VMware Fault Tolerance
VMware Fault Tolerance (FT) is another form of VM clustering developed by VMware for systems that require extreme uptime. One of the most compelling features of FT is its ease of setup. FT is simply a check box that can be enabled. Compared to traditional clustering that requires specific configurations and in some instances cabling, FT is simple but powerful.
How does it work?
When protecting VMs with FT, a secondary VM is created in lockstep of the protected VM, the first VM. FT works by simultaneously writing to the first VM and the second VM at the same time. Every task is written twice. If you click on the Start menu on the first VM, the Start menu on the second VM will also be clicked. The power of FT is its capability to keep both VMs in sync.
If the protected VM should go down for any reason, the secondary VM immediately takes its place, seizing its identity and its IP address, continuing to service users without an interruption. The newly promoted protected VM then creates a secondary for itself on another host and the cycle restarts.
To clarify, let's see an example. If you wanted to protect an Exchange server, you could enable FT. If for any reason the ESX/ESXi host that is carrying the protected VM fails, the secondary VM kicks in and assumes its duties without an interruption in service.
The table below outlines the different High Availability and clustering technologies that you have access to with vSphere and highlights limitations of each.

Fault Tolerance requirements
Fault Tolerance is no different from any other enterprise feature in that it requires certain prerequisites to be met before the technology can function properly and efficiently. These requirements are outlined in the following list and broken down into the different categories that require specific minimum requirements:
- Host requirements:
- FT-compatible CPU. Check this VMware KB article for more information.
- Hardware virtualization must be enabled in the bios.
- Host's CPU clock speeds must be within 400 MHz of each other.
- VM requirements:
- VMs must reside on supported shared storage (FC, iSCSI and NFS).
- VMs must run a supported OS.
- VMs must be stored in either a VMDK or a virtual RDM.
- VMs cannot have thinly provisioned VMDK and must be using an Eagerzeroedthick virtual disk.
- VMs cannot have more than one vCPU configured.
- Cluster requirements:
- All ESX/ESXi hosts must be same version and same patch level.
- All ESX/ESXi hosts must have access to the VM datastores and networks.
- VMware HA must be enabled on the cluster.
- Each host must have a vMotion and FT Logging NIC configured.
- Host certificate checking must also be enabled.
It is highly advisable that in addition to checking processor compatibility with FT, you check your server's make and model compatibility with FT against the VMware Hardware Compatibility List (HCL).
While FT is a great clustering solution, it is important to note that it also has certain limitations. For example, FT VMs cannot be snapshotted, and they cannot be Storage vMotioned. As a matter of fact, these VMs will automatically be flagged DRS-Disabled and will not participate in any dynamic resource load balancing.
How to enable FT
Enabling FT is not difficult, but it does involve configuring a few different settings. The following settings need to be properly configured for FT to work:
- Enable Host Certificate Checking: To enable this setting, log on to your vCenter server and click on Administration from the File menu and click on vCenter Server Settings. In the left pane, click SSL Settings and check the vCenter Requires Verified Host SSL Certificates box.
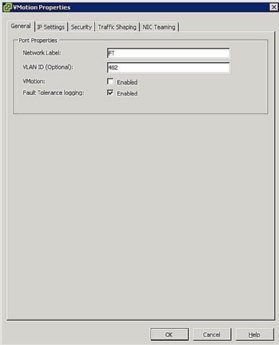
![FT port group settings]()
Figure 5. FT port group settings - Configure Host Networking: The networking configuration for FT is easy and follows the same steps and procedures as vMotion, except instead of checking the vMotion box, check the Fault Tolerance Logging box as shown in Figure 5.
- Turning FT On and Off: Once you have met the preceding requirements, you can now turn FT on and off for VMs. This process is also straightforward: Find the VM you want to protect, right-click it, and select Fault Tolerance>Turn On Fault Tolerance.
While FT is a first generation clustering technology, it works impressively well and simplifies overcomplicated traditional methods of building, configuring, and maintaining clusters. FT is an impressive technology for an uptime standpoint and from a seamless failover standpoint.